
Introduction
Most professionals don't have an email problem — they have a triage problem. Knowing which messages need action, which need a reply, and which can wait is the real bottleneck.
Email intent classification is the NLP-driven process of automatically identifying the purpose behind an email — whether a sender is asking a question, making a request, reporting a problem, or scheduling a meeting — and assigning it a predefined label accordingly.
For professionals, developers, and operations teams handling high email volumes, this distinction matters. Manual triage adds cognitive load and slows response times. Research shows professionals spend 28% of their workweek managing email, receiving an average of 117 emails daily and facing interruptions every two minutes.
This guide covers:
- How the classification process works end-to-end
- Which NLP approaches are used
- What makes classification accurate or unreliable
- When it is — and is not — the right solution
Key Takeaways
- Email intent classification uses NLP to automatically detect the purpose behind an email and assign it to predefined categories such as question, request, scheduling, or complaint
- Unlike general text classification, it processes subject lines, body content, thread context, and multi-part intentions at once
- NLP approaches range from rule-based keyword systems to fine-tuned transformer models like BERT and prompt-based LLMs
- The biggest barriers are low-quality training data, overlapping categories, and privacy constraints on real email examples
- Production systems need confidence thresholds, fallback logic, and ongoing retraining as communication patterns evolve
What Is Email Intent Classification?
Email intent classification is a supervised NLP task that maps the content of an incoming email — its subject, body, and sometimes thread history — to a predefined intent label such as "scheduling request," "support complaint," or "information sharing."
The goal is not to describe what an email is about — that's topic modelling. Intent classification identifies what the sender wants to happen: a reply, an action, a meeting, or an acknowledgement. In other words, it captures the functional goal behind the message.
How It Differs from Related Processes
These three concepts are frequently confused, but they solve entirely different problems:
| Process | What It Asks | Output |
|---|---|---|
| Spam filtering | Is this email legitimate? | Binary: spam / not spam |
| Sentiment analysis | What is the emotional tone? | Positive / negative / neutral |
| Intent classification | What does the sender want to happen? | Multi-class label: action, request, complaint, etc. |
A complaint email, for example, carries negative sentiment — but its intent is "problem reporting." Treating sentiment as a proxy for intent means your system flags frustration without knowing what to do about it. Teams that conflate these processes end up with inboxes that detect tone but can't prioritise by urgency or required action type.
Why Email Intent Classification Matters in Email Management
Scale is the core problem. Professionals spend 28% of their workweek managing email, and global email traffic reached 376.4 billion emails per day in 2025, projected to grow to 392.5 billion by 2026.
Intent classification enables:
- Automated routing — sending emails to the right team or person without manual review
- Intelligent prioritization — surfacing urgent action requests above informational messages
- Automated responses — triggering replies for predictable intent categories like scheduling or FAQs
- Task extraction — identifying action items embedded in email threads and linking them to to-do lists
Without it, inboxes default to sorting by time or sender — which means high-priority action requests get buried under informational messages, and response errors compound as volume scales.
Systems like NewMail AI use intent-based categorization to move beyond sender-based rules, classifying emails based on meaning and urgency to help teams respond faster and avoid missing critical communications.
How Email Intent Classification Works: The NLP Pipeline
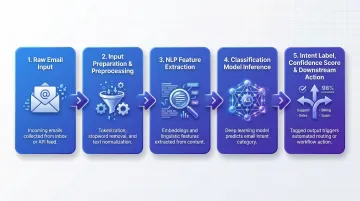
Understanding the pipeline helps clarify where accuracy is won or lost. A complete email intent classification system moves through five stages:
- Raw email input
- Input preparation and preprocessing
- NLP feature extraction
- Classification model inference
- Intent label with confidence score → downstream action (routing, prioritisation, response suggestion)
Step 1: Input Preparation
Email input is not just body text. Effective systems combine the subject line and body with clear structural markers (e.g., "SUBJECT: ... BODY: ..."). Intent is often expressed more explicitly in subjects, while context and detail appear in the body. Omitting either degrades accuracy.
Preprocessing decisions include:
- Lowercasing, removing boilerplate signatures and disclaimers, normalising contractions and emojis
- Handling thread history — whether to use only the most recent message or include prior turns
- Extracting signature blocks and reply lines using machine learning methods, which can detect signatures with over 97% accuracy
These choices directly affect what the model learns. Tools like NewMail AI analyse full email threads rather than only the latest message to maintain context fidelity and ensure replies stay accurate and complete.
Step 2: NLP Processing and Model Selection
Model approaches range from least to most complex:
Rule-based keyword/regex matching — fast, brittle, good for narrow domains with predictable language patterns.
Classical ML with TF-IDF features — lightweight, interpretable, needs manual feature engineering. Uses classifiers like SVM or logistic regression.
Fine-tuned transformer models like BERT or DistilBERT — high accuracy, requires labelled data and GPU resources. Uses the [CLS] token for sequence classification. DistilBERT is 40% smaller, 60% faster, and retains 97% of BERT's performance, making it a practical choice for production email pipelines.
LLM-based prompting with GPT-style models — flexible, zero-shot capable, higher latency and cost, less consistent output.
Of these approaches, transformer models are the dominant production choice for email intent. The reason is contextual meaning: they distinguish an email that mentions "meeting" as a scheduling request from one that mentions it as a status update, something rule-based and classical ML systems cannot reliably do.
Step 3: Classification Output and Confidence Scoring
The classifier outputs probability scores across all intent labels. The highest-probability label becomes the predicted intent. Confidence scores (0 to 1) indicate how certain the model is.
Scores below a defined threshold should trigger fallback behaviour rather than a forced prediction. Common fallback options include:
- Routing the message to a human reviewer
- Presenting multiple possible intent labels for manual selection
- Defaulting to a safe category such as "review required"
This matters because email language is frequently ambiguous or multi-intent. A message that is simultaneously a question and a scheduling request needs to be handled carefully. Systems without confidence handling will force incorrect single-label predictions, degrading downstream routing accuracy.
Key Factors That Affect Email Intent Classification Accuracy
Dataset Quality and Taxonomy Design
The intent label schema must be mutually exclusive and meaningful in context. Vague categories like "general enquiry" create overlap that confuses the model. Each label should map to a distinct downstream action.
Few properly labelled public email datasets exist due to privacy constraints. The Enron dataset (~0.5M messages from ~150 users) is the only substantial collection of "real" public email, originally made public during a legal investigation. Other datasets like Avocado are restricted by organisational agreements.
The scarcity of labelled public data pushes teams toward synthetic data generation, back-translation, or paraphrasing for augmentation — which introduces its own class balance challenges.
Training Data Volume and Class Balance
Models trained on imbalanced datasets — too many "information" emails, too few "complaint" examples — underperform on minority classes.
Data augmentation techniques address this:
- Rewriting emails with different phrasing while preserving meaning (paraphrasing)
- Substituting words with synonyms to expand vocabulary diversity
- Generating structural variations from common email templates
Macro-F1 score is the right metric here rather than raw accuracy. Macro-F1 treats all classes equally, preventing majority classes from skewing the evaluation.

Privacy Constraints on Real Email Data
Email content is sensitive. Most organisations cannot freely use real emails for model training without consent.
Weak supervision approaches address this:
- Using enterprise signals (calendar accepts, reply types) as proxy labels — research shows this improves intent detection when combined with limited annotated data
- Writing labelling functions via tools like Snorkel (heuristics, rules, patterns) instead of hand-labelling each example
NewMail AI handles privacy through ephemeral processing: emails are transferred securely to AI partners, analysed, then discarded from memory immediately. No email content is stored or used for model training.
Model Selection Tradeoffs in Production
The core tradeoff comes down to two approaches:
| Approach | Strengths | Limitations |
|---|---|---|
| Fine-tuned transformer | Lower inference cost, predictable behaviour | Requires labelled training data |
| LLM-based (zero-shot) | No labelled data needed, fast to prototype | Higher per-query cost, harder to audit |

At production scale with strict privacy requirements, fine-tuned models with local inference are the practical choice over cloud-dependent LLM APIs.
Common Issues and Misconceptions
Several misconceptions trip up teams before they write a single line of code. Here are the ones that cause the most problems in practice.
Intent Classification vs. Topic Labelling
Labelling an email as "HR" or "Finance" is topic classification. Labelling it as "action request" or "scheduling" is intent classification. Many teams conflate the two and build systems that route by subject matter but fail to prioritise by urgency or required action type.
Off-the-Shelf Models Won't Work Without Domain Examples
General-purpose models do not understand organisation-specific terminology, email conventions, or the difference between a "request" in a legal context versus a sales context. Off-the-shelf models need labelled examples from the deployment domain to be reliable.
Intent Is Not the Same as Tone
A model trained for intent classification should not be expected to detect urgency, frustration, or sarcasm — that is a sentiment or tone task. Systems that conflate the two produce mislabelled outputs when a calm-sounding email contains a time-sensitive request or when an angry-sounding email is simply informational.
When Intent Classification Is the Wrong Tool Entirely
For small volumes or narrow, predictable workflows, rule-based keyword matching is often the better choice. It's faster to implement, easier to audit, and performs comparably. Deploying a transformer model for a team receiving 50 emails per day with three consistent intent types adds complexity that isn't justified by the performance gain:
- Model maintenance and periodic retraining cycles
- Infrastructure overhead for hosting and inference
- Labelling pipelines to handle data drift over time
Frequently Asked Questions
What is email intent classification?
Email intent classification is the NLP task of automatically identifying what a sender wants to accomplish in an email — such as asking a question, making a request, or scheduling a meeting — and assigning that email to a predefined intent label to enable automated routing, prioritisation, or response.
What are the different email classifications?
Common intent categories include:
- Question or information request
- Action request
- Scheduling
- Information sharing or update
- Complaint or problem report
- Feedback
The specific taxonomy varies by organisation and should be designed around distinct downstream actions — routing to support, triggering calendar invites, or escalating to management.
What is the BERT model for classification?
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model that can be fine-tuned for sequence classification tasks by adding a classification layer on top of its [CLS] token output. It captures deep contextual meaning and outperforms classical ML approaches on email intent tasks when sufficient labelled data is available.
How do you prepare a dataset for text classification?
The core steps are:
- Define a clear label schema
- Collect labelled examples covering each class proportionally
- Preprocess text (lowercase, remove boilerplate, normalise)
- Split into train/validation/test sets with inter-annotator agreement checks
Macro-F1 is the preferred evaluation metric for imbalanced datasets.
What is the difference between email intent classification and spam filtering?
Spam filtering is a binary task that determines whether an email is legitimate or unwanted. Intent classification assumes the email is legitimate and identifies what the sender wants to achieve. They use similar NLP techniques but serve different purposes and are typically separate components in an email management system.
What NLP techniques are used for email intent classification?
Common techniques include:
- Keyword and regex matching — simple rule-based systems
- TF-IDF with SVM — lightweight deployments
- Fine-tuned transformers (BERT, DistilBERT) — production-grade accuracy
- Prompt-based LLMs — zero-shot or few-shot prototyping
Fine-tuned transformers dominate production environments for their balance of accuracy and efficiency.


